Introdução
Escolher a ferramenta de segurança de código certa pode determinar o sucesso ou o fracasso da sua estratégia de segurança de desenvolvimento. Snyk e Semgrep são frequentemente comparados por sua abordagem focada no desenvolvedor para encontrar vulnerabilidades precocemente. Ambos ajudam as equipes a entregar código mais seguro, integrando verificações de segurança no desenvolvimento – mas cada um tem um foco diferente. Esta comparação explora como eles se comparam e por que a escolha é importante para líderes técnicos responsáveis pela entrega de software seguro.
TL;DR
Snyk e Semgrep ajudam a proteger sua base de código, mas eles se concentram em camadas diferentes – e ambos têm pontos cegos. Snyk se destaca na varredura de dependências de código aberto e Container, enquanto Semgrep se especializa em análise estática de código. Aikido Security une ambos os mundos em uma única plataforma, com muito menos falsos positivos e integração mais simples – tornando-o a melhor escolha para equipes de segurança modernas.
Visão geral de Snyk e Semgrep
Snyk
Snyk é uma plataforma de segurança voltada para o desenvolvedor, conhecida por encontrar vulnerabilidades em bibliotecas open-source e outros componentes. Começou com análise de composição de software (SCA) para identificar dependências vulneráveis, e mais tarde expandiu para a varredura de imagens de Container, Infrastructure-as-Code e até mesmo código estático via Snyk Code. A força do Snyk é a integração perfeita em fluxos de trabalho de desenvolvimento (como GitHub, pipelines de CI/CD e IDEs) para alertar os desenvolvedores precocemente sobre riscos. Ele enfatiza a segurança “shift-left”, tornando-o popular entre equipes DevOps ágeis. No entanto, a abordagem ampla do Snyk vem com compensações em profundidade e ruído, que discutiremos.
Semgrep
Semgrep é uma ferramenta open-source de análise estática (SAST) focada em escanear seu código-fonte em busca de bugs e problemas de segurança. Ele utiliza correspondência de padrões flexível e baseada em regras para detectar desde vulnerabilidades de segurança até erros de qualidade de código. Semgrep é leve e sensível à linguagem, permitindo que seja executado rapidamente em pipelines de CI sem uma configuração complexa. Seu principal atrativo é a personalização: as equipes podem escrever suas próprias regras em YAML para atingir padrões específicos, dando grande poder para adaptar as varreduras à sua base de código. Esse design centrado no desenvolvedor tornou o Semgrep um favorito para aqueles que desejam controle prático sobre a varredura de código. Mas o foco restrito do Semgrep (apenas código) significa que ele não cobrirá vulnerabilidades de pacotes open-source, Containers ou problemas de infraestrutura por padrão, abordando apenas parte do quebra-cabeça da segurança.
Comparação Recurso por Recurso
Capacidades de Varredura de Segurança
Cobertura do Snyk: Snyk oferece um amplo conjunto de recursos de varredura sob um único guarda-chuva. É mais forte em SCA (análise de dependências open-source) – usando um banco de dados de vulnerabilidades para sinalizar bibliotecas de risco em seu aplicativo. Snyk também escaneia imagens de Container e configurações de IaC (Infrastructure as Code) em busca de problemas conhecidos, visando proteger toda a stack. Além disso, o Snyk Code oferece análise SAST para seu código, embora esta seja uma área mais recente para o Snyk e não sua principal força. Na prática, o Snyk é mais conhecido por detectar vulnerabilidades conhecidas (como aquela biblioteca desatualizada com um CVE) e ajudar os desenvolvedores a corrigi-las precocemente.
Cobertura do Semgrep: Semgrep, em contraste, foca intensamente na análise estática de código. Ele se destaca na detecção de falhas de codificação, padrões inseguros e bugs de lógica em seu próprio código, utilizando centenas de regras escritas pela comunidade (e a opção de escrever regras personalizadas). Ele não possui um banco de dados integrado de CVEs para pacotes open-source ou varredura de Containers/IaC de forma nativa. (Semgrep possui add-ons separados como "Semgrep Supply Chain" e "Semgrep Secrets", mas são ferramentas distintas em seu ecossistema.) O principal caso de uso é encontrar problemas no próprio código da aplicação – por exemplo, um uso inseguro de eval ou uma higienização de entrada ausente – em vez de vulnerabilidades em componentes de terceiros. Isso significa que o Semgrep pode descobrir bugs de segurança que o scanner de dependências do Snyk pode ignorar, mas o Semgrep perderá qualquer coisa fora do código (como uma versão de biblioteca vulnerável ou uma imagem Docker mal configurada).
Principal Diferença: Snyk adota uma abordagem mais ampla e centrada em componentes (código, dependências, Containers, configuração), enquanto Semgrep adota uma abordagem mais profunda e centrada em código. Se você precisa de uma ferramenta para escanear seus pacotes open-source em busca de falhas conhecidas, Snyk te atende. Se você está mais preocupado com o código personalizado que sua equipe escreve, a análise estática do Semgrep é mais direta. Ambas as ferramentas deixam lacunas – a análise estática de código do Snyk não é tão completa quanto a do Semgrep, e o Semgrep não oferece cobertura para vulnerabilidades da cadeia de suprimentos por si só. Líderes técnicos frequentemente acabam usando múltiplas ferramentas ou uma plataforma combinada (como Aikido) para cobrir ambas as bases.
Integração e Fluxo de Trabalho DevOps
Integração Snyk: Um dos maiores pontos de venda do Snyk é o quão bem ele se encaixa nos fluxos de trabalho existentes dos desenvolvedores. Ele oferece plugins para IDEs populares (para que os desenvolvedores recebam alertas instantâneos enquanto codificam), integrações nativas com GitHub/GitLab/Bitbucket e hooks de pipeline de CI/CD que podem interromper builds por problemas de segurança. O serviço de Cloud do Snyk monitora seus repositórios; sempre que você abre um pull request ou envia um novo código, o Snyk pode escanear e relatar problemas na UI do provedor Git. Os desenvolvedores apreciam que o Snyk exibe os resultados diretamente onde eles trabalham – embora uma desvantagem seja que o Snyk frequentemente direciona os usuários para seu dashboard web para detalhes, causando troca de contexto.
Notavelmente, Snyk é uma plataforma SaaS gerenciada, o que significa que seu código (ou manifesto de dependência) é carregado para a Cloud deles para análise. Isso facilita a configuração (sem servidores para manter), mas algumas empresas relutam em enviar o código-fonte para fora, e a falta de opções on-premise do Snyk pode ser um obstáculo para ambientes altamente regulamentados. Além disso, o Snyk suporta principalmente repositórios na Cloud (se usando a integração SCM do Snyk) – mudanças como a renomeação de um repositório podem até quebrar a conexão. No geral, integrar o Snyk é simples se você já está baseado em Cloud e usando ferramentas de desenvolvedor comuns. É uma solução "plug and play" para equipes que praticam DevSecOps, com a ressalva de que você estará trabalhando dentro do ecossistema do Snyk.
Integração Semgrep: A abordagem do Semgrep é mais flexível e controlada pelo desenvolvedor. Sendo open-source, você pode executar o CLI do Semgrep localmente ou na CI com o mínimo de complicação – não há necessidade de se inscrever em um serviço, se não quiser. Isso significa que você pode integrar as varreduras do Semgrep em qualquer lugar: um hook de pré-commit, um workflow do GitHub Actions, um pipeline do Jenkins, o que você quiser. Muitas equipes usam o Semgrep GitHub Action oficial ou as integrações de CI/CD para adicionar verificações do Semgrep em cada pull request, que então deixam comentários diretamente na revisão de código. Este feedback in-line (ver os problemas como comentários no seu PR) facilita para os desenvolvedores corrigirem problemas de código sem mudar o contexto para outro aplicativo.
O Semgrep também possui uma plataforma SaaS opcional (Semgrep App) que agrega resultados, fornece uma UI e recursos de colaboração em equipe – similar à interface do Snyk, mas opcional. É importante ressaltar que você pode executar o Semgrep totalmente offline, se necessário, o que atrai equipes com requisitos rigorosos de privacidade de código. A curva de aprendizado para integrar o Semgrep é baixa para uso básico (o CLI é direto), mas ajustá-lo para o seu ambiente pode exigir a escrita ou seleção das regras certas, o que é um passo extra que abordaremos em Precisão. Em termos de dependências de plataforma, o Semgrep é agnóstico a ferramentas: não importa qual sistema Git ou CI você usa, e não impõe uma hospedagem de repositório específica (ao contrário, por exemplo, de soluções apenas para GitHub).
Essa flexibilidade torna o Semgrep adequado para diversos workflows, embora com mais ajuste manual em comparação com as integrações 'click and go' do Snyk.
Precisão e Desempenho
Falsos Positivos e Ruído: A precisão é um fator crítico para qualquer ferramenta de segurança – muitos falsos positivos, e os desenvolvedores começam a ignorar a ferramenta. Aqui, tanto Snyk quanto Semgrep enfrentaram críticas, mas de maneiras diferentes. A varredura SAST (código) do Snyk tem reputação de altas taxas de falsos positivos em certas linguagens. Os desenvolvedores frequentemente relatam ser inundados com descobertas que não são vulnerabilidades reais, o que pode corroer a confiança na ferramenta. Uma razão é que as regras do Snyk são em sua maioria generalizadas e proprietárias, dando aos usuários visibilidade ou controle limitados para ajustá-las.
Se o Snyk sinaliza algo, você pode ignorá-lo ou corrigi-lo – mas você não consegue ajustar facilmente a lógica da regra. Essa abordagem de 'caixa preta' às vezes deixa as equipes de segurança frustradas quando sabem que uma descoberta não é um problema, mas continuam a vê-la sinalizada. O Semgrep, por outro lado, também pode produzir resultados ruidosos de forma imediata. Como ele depende de regras de padrão, uma execução do Semgrep não ajustada pode sinalizar muitos problemas potenciais, incluindo pequenos problemas de estilo ou falsos positivos, dependendo dos conjuntos de regras que você usa. Na verdade, usar o Semgrep de forma eficaz frequentemente exige a curadoria de suas regras para reduzir o ruído – você pode começar com um conjunto de regras amplo e depois desativar as regras que não são relevantes ou são muito ruidosas.
A vantagem é que você tem esse controle: o Semgrep oferece visibilidade em nível de regra e a capacidade de modificar ou suprimir regras específicas, assim, com o tempo, as equipes podem reduzir significativamente os falsos positivos. Em contraste, o Snyk não permite que você ajuste suas regras integradas, o que pode parecer um instrumento grosseiro em comparação.
Falhas e Pontos Cegos: A precisão não se trata apenas de falsos alarmes; é também sobre o que cada ferramenta falha em detectar. Como o Snyk depende de dados de vulnerabilidades conhecidas para muitas de suas descobertas, ele pode falhar em detectar problemas de código personalizado que não possuem um CVE ou assinatura conhecida. O Snyk Code (seu SAST) tenta encontrá-los, mas, como observado, é um player mais recente e pode não detectar bugs lógicos complexos que o Semgrep poderia capturar com uma regra bem escrita.
Por outro lado, o Semgrep pode não reconhecer que uma determinada dependência é vulnerável (a menos que você tenha escrito uma regra para detectar uma string de versão específica ou padrão de uso), então ele poderia perder completamente um problema como “atualize esta biblioteca, ela possui uma vulnerabilidade RCE conhecida.” Cada ferramenta tem pontos cegos: o Snyk pode ignorar certos problemas de fluxo de dados ou qualidade no código, e o Semgrep pode ignorar versões de bibliotecas vulneráveis ou problemas de configuração por design.
Velocidade e Desempenho: Ambas as ferramentas são projetadas para serem relativamente rápidas e amigáveis à CI, mas seus perfis de desempenho diferem. As varreduras do Snyk, especialmente para dependências, são geralmente rápidas (uma varredura do Snyk Open Source pode levar segundos). A análise do Snyk Code é baseada na Cloud e também pode retornar resultados em menos de um minuto para bases de código moderadas. O Semgrep é executado localmente (ou em seu Container de CI) e é bastante leve dada sua abrangência – uma base de código de ~50K linhas pode ser varrida em um ou dois minutos. Em testes da comunidade, o Semgrep foi ligeiramente mais lento que o Snyk Code para varredura de código pura (por exemplo, 90 segundos vs 45 segundos em um repositório de tamanho médio), mas ainda rápido o suficiente para CI na maioria dos casos.
Ambos podem ser executados incrementalmente (apenas varrendo o código alterado) para acelerar o feedback em pull requests. Vale ressaltar que a vantagem de desempenho do Snyk vem em parte dos recursos da Cloud realizando o trabalho, enquanto a velocidade do Semgrep vem de um motor enxuto que não tenta fazer análise interprocedural profunda como ferramentas SAST empresariais mais pesadas. Nenhuma das ferramentas impacta significativamente os tempos de build quando configuradas corretamente, e ambas suportam execução em paralelo com testes. Se sua equipe valoriza feedback em tempo real, o plugin IDE do Snyk pode fornecer resultados instantâneos enquanto você digita, enquanto o modelo do Semgrep é tipicamente executar ao salvar ou commitar (embora também tenha extensões IDE, elas são menos famosas).
Em resumo, ambas as ferramentas são rápidas o suficiente para uso prático, mas esteja preparado para investir tempo em ajustar o Semgrep para evitar ser inundado por falsos positivos, e esteja ciente de que o Snyk pode ocasionalmente sinalizar dezenas de problemas que os desenvolvedores terão que filtrar.
Cobertura e Escopo
Linguagens e Frameworks: Tanto Snyk quanto Semgrep promovem suporte a múltiplas linguagens, mas sua abrangência difere. Snyk suporta muitas linguagens para análise de dependências (basicamente qualquer linguagem com um gerenciador de pacotes, do npm do JavaScript ao pip do Python e ao Maven do Java, etc.). Seu SAST (Snyk Code) atualmente suporta linguagens importantes como Java, JavaScript/TypeScript, Python, C#, Ruby, PHP e algumas outras. No entanto, usuários notaram que a cobertura de regras do Snyk varia por linguagem – o suporte a alguns ecossistemas ainda está amadurecendo.
Você vai querer verificar se o Snyk cobre profundamente os frameworks que você usa (por exemplo, ele pode lidar com padrões comuns em Spring ou Express, mas uma linguagem ou framework mais obscuro pode ter uma cobertura mais fraca). Semgrep possui uma ampla gama de linguagens suportadas para varredura de padrões – das populares (JS/TS, Python, Java, C, Go, Ruby, etc.) até as de nicho, como configurações Terraform e Kotlin. Como as regras do Semgrep são impulsionadas pela comunidade, a cobertura de linguagem frequentemente depende da disponibilidade das regras. A vantagem é que, se o Semgrep não suportar uma nova linguagem nativamente, a equipe geralmente a adiciona rapidamente (ou você pode escrever padrões personalizados com sintaxe limitada).
Para a maioria das stacks modernas, tanto Snyk quanto Semgrep suportarão sua linguagem – mas o Snyk pode não detectar todos os problemas específicos de framework até que suas regras evoluam, e o Semgrep pode exigir que você encontre/escreva regras para frameworks de ponta, já que é baseado em padrões.
Tipos de Problemas: Em termos dos tipos de problemas de segurança cobertos, o Snyk é muito abrangente para vulnerabilidades conhecidas – cobrindo não apenas falhas de código, mas também problemas de configuração (como imagens base Docker inseguras ou scripts Terraform AWS mal configurados) e vazamentos de segredos no código. É uma solução completa para muitas categorias: SAST, SCA, varredura de contêineres, varredura IaC, e até mesmo alguma conformidade de licenças para código aberto. No entanto, essa amplitude pode diluir o foco – para padrões de vulnerabilidade de código verdadeiramente complexos, o Snyk Code pode não ter uma regra, enquanto uma regra personalizada do Semgrep poderia detectá-lo. As capacidades de detecção do Semgrep se estendem a tudo o que você pode codificar como um padrão.
Pronto para uso, ele vem com regras para os riscos de aplicações web do Top 10 OWASP, credenciais hardcoded, uso inseguro de criptografia e muito mais. Mas, notavelmente, o Semgrep não possui conhecimento inerente sobre bancos de dados CVE ou benchmarks de contêineres – qualquer verificação para esses deve ser codificada em uma regra. Na prática, a comunidade do Semgrep criou regras para alguns padrões de dependência vulneráveis conhecidos (por exemplo, uso de uma API vulnerável em certas versões de biblioteca), mas isso não substitui uma ferramenta SCA dedicada. Se um líder técnico precisa de cobertura em todo o SDLC (Ciclo de Vida de Desenvolvimento de Software) – do código à Cloud – nem Snyk nem Semgrep sozinhos são suficientes. O Snyk perde aspectos dinâmicos/de tempo de execução e alguma lógica de código profunda, enquanto o Semgrep perde riscos ambientais e de dependência.
É aqui que entram plataformas combinadas ou múltiplas ferramentas. Por exemplo, o Aikido Security cobre tanto SAST quanto SCA em uma única solução para evitar essas lacunas, fornecendo uma cobertura mais ampla do que Snyk ou Semgrep individualmente.
Lacunas Notáveis: Para resumir as limitações de escopo: o foco do Semgrep é restrito – ele não varre segredos, configurações de nuvem, contêineres, etc., sem ajuda. O foco do Snyk é amplo, mas superficial na análise de código – ele pode sinalizar muitos problemas de dependência e configuração, mas ignorar algumas vulnerabilidades de código personalizadas ou produzir insights superficiais. Além disso, o Snyk possui alguns limites técnicos: por exemplo, ele não varrerá arquivos muito grandes (>1 MB) na análise de código, pulando-os silenciosamente, o que poderia deixar riscos invisíveis se você tiver arquivos de código auto-gerados gigantes ou arquivos de dados em seu repositório. O Semgrep não possui tais limites de tamanho de arquivo tipicamente, pois você controla o que varrer. Em essência, cada ferramenta cobre o que a outra omite: uma faz varredura de código aberto e ambiente, a outra faz varredura de padrões de código. A sobreposição de sua cobertura requer esforço de integração ou o uso de uma alternativa que unifique essas varreduras.
Experiência do Desenvolvedor
Facilidade de Uso: Da perspectiva de um desenvolvedor, o Snyk é muito amigável para começar – você se cadastra, conecta um repositório ou executa um comando CLI, e ele retorna resultados com referências sobre como corrigir. Sua UI é polida, e os achados frequentemente se ligam a informações adicionais (como detalhes de CVE ou exemplos de correções), o que pode ser útil. O desenvolvedor recebe correções guiadas, especialmente para vulnerabilidades de código aberto – o Snyk pode até mesmo abrir automaticamente um pull request para atualizar uma versão de dependência para você, o que é um toque agradável para equipes ocupadas. No entanto, desenvolvedores reclamaram que usar o Snyk pode se tornar um “caça-vulnerabilidades”: você corrige um problema, e a próxima varredura mostra mais, às vezes até re-reportando problemas que não são realmente problemas devido à falta de contexto. Além disso, como as informações detalhadas do Snyk estão em sua plataforma, os desenvolvedores devem sair de seu ambiente de código para fazer login no portal do Snyk para a triagem de problemas. Essa troca de contexto pode prejudicar a adoção – parece um processo externo em vez de parte da codificação.
UX do Desenvolvedor do Semgrep: O Semgrep adota uma abordagem mais integrada para a experiência do desenvolvedor. Quando configurado para comentar em pull requests, os desenvolvedores recebem feedback de segurança na própria revisão de código. Isso é muito mais imediato e mantém o fluxo de trabalho de remediação junto ao fluxo de trabalho de desenvolvimento. Os desenvolvedores podem discutir o achado diretamente no PR, ajustar o código e enviar uma correção – tudo sem precisar ir para um painel separado. Além disso, os achados do Semgrep são frequentemente diretos (“Esta linha parece um risco de injeção SQL, considere usar consultas parametrizadas”) porque as regras podem incluir mensagens personalizadas.
Essa clareza e abordagem em contexto tendem a tornar os desenvolvedores menos defensivos; parece um feedback de revisão de código em vez de uma auditoria externa. Por outro lado, o Semgrep pode exigir que os desenvolvedores se envolvam mais no ajuste de regras ou no tratamento de falsos positivos mais do que fariam com o Snyk. A curva de aprendizado para escrever uma regra Semgrep personalizada não é íngreme (especialmente para engenheiros familiarizados com codificação), mas é um trabalho adicional. Alguns desenvolvedores também acham a saída bruta do Semgrep (se não estiver usando a integração de PR) um pouco ruidosa até ser configurada. Em termos de UI, o aplicativo Semgrep (se você o usa) está melhorando, mas não é tão maduro ou abrangente quanto a interface do Snyk para rastrear problemas em projetos. É minimalista por design – combinando com a abordagem direta – mas para equipes maiores, coisas como rastreamento de fluxo de trabalho, atribuição e métricas históricas são menos desenvolvidas.
Um líder técnico pode notar que o Snyk oferece mais relatórios “corporativos” (dashboards, relatórios de conformidade, etc.), enquanto o Semgrep foca em entregar alertas aos desenvolvedores de forma oportuna. Esta é uma diferença filosófica: o Snyk tenta ser uma plataforma completa (com dashboards para gerentes), enquanto o Semgrep prioriza a integração e flexibilidade do fluxo de trabalho do desenvolvedor em detrimento de dashboards sofisticados.
Automação e Correções: Ambas as ferramentas estão evoluindo na forma como ajudam a remediar problemas. O Snyk fornece pull requests de correção automatizadas para problemas de dependência e mostrará exemplos de correções para problemas de código (muitas vezes apenas um trecho de sua base de conhecimento). O Semgrep introduziu Semgrep Autofix/Assistant, que usa IA para propor alterações de código reais para certas descobertas. Por exemplo, se o Semgrep encontrar um uso perigoso de eval, o assistente pode sugerir um trecho de código mais seguro para substituí-lo. O feedback inicial indica que isso pode economizar tempo do desenvolvedor, embora não seja perfeito. A abordagem do Snyk é mais tradicional – ele não altera automaticamente seu código (além das dependências), mas oferece orientação.
Dependendo da preferência dos seus desenvolvedores, eles podem gostar da tentativa de autocorreções do Semgrep, ou podem preferir as referências explícitas do Snyk. Tratamento de Falsos Positivos: Mais uma observação sobre a experiência do desenvolvedor: quando uma descoberta não é realmente um problema, quão facilmente ela pode ser descartada? No Snyk, você pode marcar itens como ignorados (com opções de expiração), mas se a regra for acionada em um código ligeiramente diferente, você a verá novamente.
No Semgrep, como você pode modificar ou desativar a regra inteiramente, você tem uma solução mais permanente (embora precise ter cuidado para não desativar algo real). Desenvolvedores que odeiam ver o mesmo falso alarme repetidamente podem apreciar que o Semgrep aprende com o feedback (quando você sinaliza uma descoberta como falsa, você pode ajustar a regra para parar de sinalizar esse padrão). Com o Snyk, os desenvolvedores às vezes sentem que estão presos às peculiaridades da ferramenta e precisam conviver com certas não-questões ou filtrá-las manualmente a cada vez.
Preços e Manutenção
Preços do Snyk: O Snyk é um SaaS comercial com um modelo de preços em camadas. Ele oferece um nível gratuito para projetos de pequena escala ou de código aberto (com alguns limites no número de testes), mas o uso sério em nível de equipe ou empresarial requer um plano pago. O Snyk geralmente cobra por licença de desenvolvedor (e possivelmente por projeto para certos produtos), o que pode se tornar caro à medida que a equipe de engenharia cresce. As organizações frequentemente descobrem que, ao integrar o Snyk em dezenas de repositórios e desenvolvedores, a fatura aumenta acentuadamente – às vezes levando-as a escanear seletivamente apenas repositórios críticos para controlar os custos. O plano empresarial do Snyk adiciona recursos como relatórios de SLA personalizados e suporte on-premise (em casos raros), mas estes vêm com um custo premium. Em resumo, o Snyk pode ser uma das ferramentas mais caras neste espaço, e orçá-lo é uma consideração para um líder de segurança.
Preços do Semgrep: O núcleo do Semgrep é de código aberto e gratuito para usar. Isso significa que você pode executar varreduras ilimitadas via CLI ou CI sem pagar um centavo, o que é uma grande vantagem para equipes com orçamento limitado. A empresa por trás do Semgrep oferece planos empresariais pagos (Semgrep Team/Enterprise) que incluem um aplicativo Cloud gerenciado, bibliotecas de regras adicionais e suporte. Esses planos também são tipicamente precificados por licença (ou seja, por desenvolvedor ou por licença de projeto). Mesmo assim, dado que você tem a liberdade de usar a versão gratuita, as equipes frequentemente começam com o Semgrep Community Edition e só consideram pagar se precisarem da conveniência da plataforma centralizada ou de recursos avançados.
A manutenção, no entanto, é um custo com o Semgrep – a sobrecarga operacional de gerenciar regras e ferramentas. Em vez de uma assinatura, você gasta tempo de engenharia para manter as regras atualizadas e triar as descobertas. Para uma equipe pequena com alguns repositórios, esse custo é insignificante. Mas para uma organização maior, manter um grande conjunto de regras e supressões personalizadas do Semgrep pode se tornar um esforço significativo. Algumas empresas mitigam isso usando os pacotes de regras da comunidade e contribuindo de volta, terceirizando efetivamente parte da manutenção para a comunidade. Ainda assim, é importante considerar que o Semgrep não é 'gratuito' se você contar o tempo de engenharia para ajustá-lo em escala.
Manutenção e Infraestrutura: Com o Snyk, a manutenção da infraestrutura é mínima – é um SaaS Cloud, então você não mantém servidores (a menos que opte por um appliance on-premise para o Snyk, o que é incomum e pode incorrer em custo extra). Você precisa gerenciar a integração (garantindo que cada repositório esteja vinculado, cada pipeline tenha a etapa do Snyk, etc.) e manter o CLI atualizado se o usar lá. O Snyk se encarrega de atualizar os bancos de dados de vulnerabilidades e melhorar as regras por parte deles (às vezes, essas atualizações também podem introduzir novas descobertas da noite para o dia). O Semgrep, quando auto-hospedado, exige que você mantenha o CLI atualizado (o que é tão simples quanto um pip install ou download binário no CI).
Se você usa o Semgrep App, ele é SaaS e eles o mantêm, mas você ainda pode hospedar uma implantação interna se preferir (o que requer um servidor e alguma configuração). Geralmente, a manutenção do Semgrep é mais sobre conteúdo (regras) do que sobre a própria ferramenta.
Transparência de Preços: Vale ressaltar que os preços empresariais tanto do Snyk quanto do Semgrep podem ser um pouco complexos. O Snyk frequentemente negocia acordos empresariais personalizados, e os preços do Semgrep para o nível pago não são divulgados publicamente, geralmente exigindo contato para uma cotação. É aqui que a Aikido Security se diferencia: a Aikido oferece um modelo de preços mais simples e fixo que não o penaliza por adicionar mais projetos ou desenvolvedores. Ele tende a ser mais previsível e acessível em escala em comparação com os custos por licença dos planos pagos do Snyk ou do Semgrep.
Prós e Contras de Cada Ferramenta

Prós do Snyk:
- Ampla Cobertura de Segurança: Varre código, dependências de código aberto, Containers, arquivos de configuração e muito mais em uma única plataforma, proporcionando uma ampla rede de segurança.
- Integração Amigável para Desenvolvedores: Fácil de integrar a repositórios, CI/CD e IDEs para varredura automatizada e feedback rápido nos fluxos de trabalho de desenvolvimento.
- Correções Acionáveis para Dependências: Fornece orientação clara para atualização e até mesmo pull requests automáticos para corrigir bibliotecas vulneráveis, simplificando a remediação para problemas de SCA.
- UI Intuitiva: Dashboard refinado com detalhes de vulnerabilidade, dicas de priorização e links para informações adicionais, o que é útil para desenvolvedores que estão aprendendo a corrigir problemas.
Contras do Snyk:
- Altos Falsos Positivos em SAST: Sua análise estática de código frequentemente sinaliza muitos não-problemas, causando fadiga de alertas entre os desenvolvedores.
- Análise de Código Superficial: Forte na detecção de CVEs conhecidas, mas mais fraco na localização de bugs complexos em código personalizado (sem análise avançada de fluxo de dados ou tempo de execução como algumas ferramentas SAST).
- Caro em Escala: Os preços por desenvolvedor podem se tornar elevados para grandes equipes, e os recursos avançados estão bloqueados em planos empresariais.
- Personalização Limitada: Regras de código fechado sem capacidade de ajustar a lógica de detecção; você deve esperar por atualizações do fornecedor ou usar mecanismos de ignorar desajeitados se algo estiver falhando.
- Potencial Atrito na Integração: Requer o upload de dados para um serviço Cloud (o que algumas organizações não podem permitir), e a plataforma pode pular a varredura de arquivos grandes ou certos arquivos sem aviso claro.

Semgrep Prós:
- Análise Estática Poderosa: Excelente na detecção de vulnerabilidades de código e anti-padrões com regras leves, cobrindo muitas linguagens e frameworks.
- Altamente Personalizável: Engenheiros de segurança podem escrever regras personalizadas em YAML para direcionar os padrões relevantes para sua base de código. Essa flexibilidade permite encontrar problemas exclusivos da sua aplicação que ferramentas genéricas perderiam.
- Rápido e Leve: Executa rapidamente em pipelines de CI com impacto mínimo nos tempos de build, e não requer infraestrutura pesada ou recursos de Cloud para operar.
- Fluxo de Trabalho Focado no Desenvolvedor: Integra-se a pull requests e ferramentas de desenvolvimento, fornecendo feedback imediato e em contexto que os desenvolvedores consideram útil (parece parte da revisão de código, e não um scanner externo).
- Código Aberto e Transparente: O motor de varredura e muitos conjuntos de regras são abertos, permitindo às equipes total visibilidade sobre quais verificações estão sendo realizadas e a capacidade de ajustá-las ou estendê-las. Sem caixas pretas.
Desvantagens do Semgrep:
- Foco Restrito: Cobre apenas código (SAST). Falta varredura integrada para vulnerabilidades de dependências open-source, Secrets, Containers ou IaC, abordando uma fatia limitada do espectro de segurança. As equipes precisarão de ferramentas adicionais para cobertura total.
- Ruidoso Sem Ajustes: Conjuntos de regras padrão podem gerar muitos achados, incluindo falsos positivos, o que exige ajustes iniciais para filtrar regras irrelevantes e reduzir o ruído. Esse ajuste exige expertise em segurança e adaptação contínua à medida que o código evolui.
- Custo de Manutenção: Gerenciar uma grande biblioteca de regras personalizadas e mantê-las atualizadas à medida que a base de código e o cenário de ameaças mudam é um esforço contínuo. Em escala empresarial, isso pode se tornar oneroso sem engenheiros de AppSec dedicados.
- Contexto e Priorização Limitados: Os achados são baseados em correspondências de padrões sem um contexto mais amplo (por exemplo, se o código vulnerável é realmente alcançável ou explorável em tempo de execução). Isso pode resultar em uma longa lista de problemas sem orientação sobre quais realmente importam, ao contrário de ferramentas que incorporam o contexto de risco.
- Menos Recursos Empresariais: Faltam alguns dos recursos de governança, relatórios e conformidade que organizações maiores podem desejar (por exemplo, logs de auditoria, acesso baseado em função, verificações de conformidade prontas para uso). Semgrep está melhorando nesse aspecto, mas seu foco principal continua sendo capacitar desenvolvedores em vez de satisfazer auditores.
Aikido Security: A Melhor Alternativa
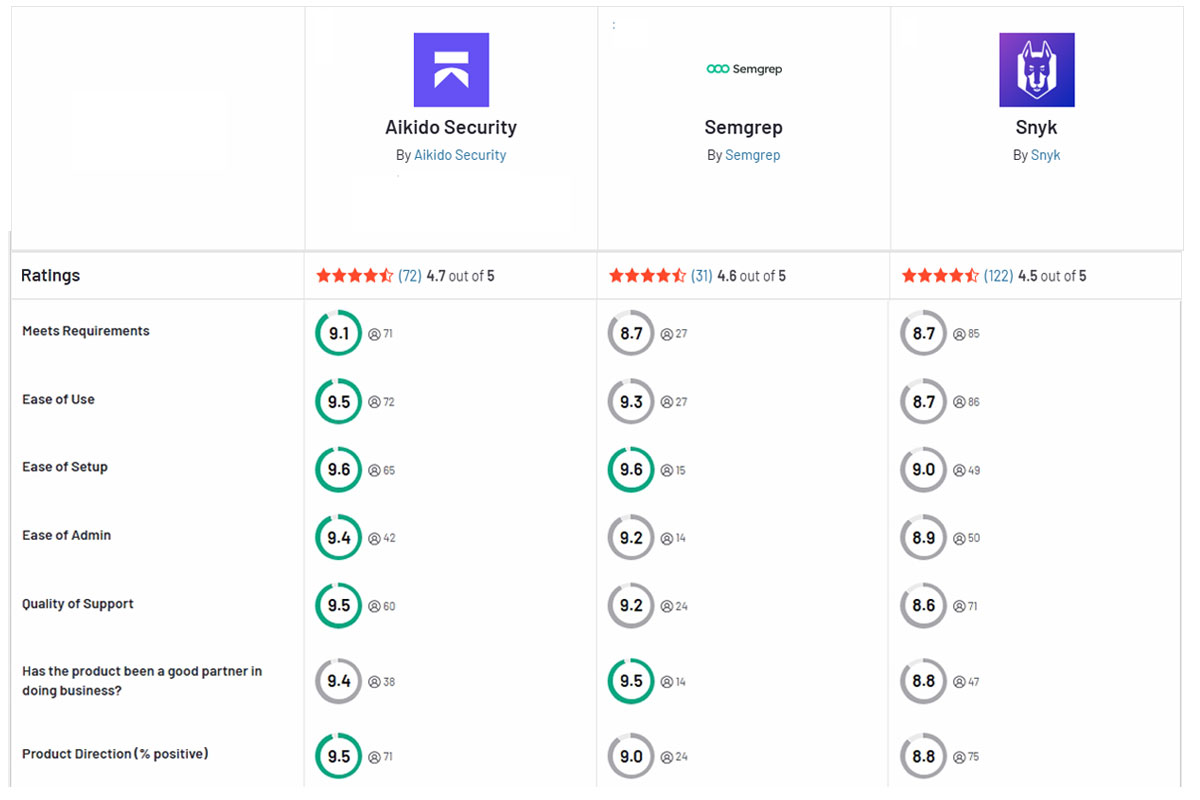
Equipes de segurança modernas frequentemente precisam dos pontos fortes de Snyk e Semgrep sem as dores de cabeça. Aikido Security foi construído como uma solução unificada que combina varredura de código e análise de dependências em uma única plataforma amigável para desenvolvedores. Ele cobre SAST e SCA juntos, para que você não seja forçado a lidar com várias ferramentas.
Ao reunir múltiplos tipos de varredura em um só lugar, Aikido pode contextualizar vulnerabilidades e filtrar falsos positivos – reduzindo o ruído em até 95%. Menos falsos alarmes significam que os desenvolvedores realmente confiam nos achados. A integração é perfeita: Aikido se conecta aos seus repositórios e pipelines como Snyk, mas também entrega resultados em linha como Semgrep, minimizando o atrito. As principais vantagens vêm da automação inteligente – por exemplo, correções e priorização impulsionadas por IA – economizando tempo da sua equipe.
Ao contrário de fornecedores legados, Aikido mantém as coisas diretas e transparentes. O preço é fixo e previsível, evitando os altos custos por licença que tornam Snyk ou Semgrep caros em escala. Em resumo, Aikido une ambos os mundos em uma única plataforma com muito menos ruído e complexidade, tornando-o uma escolha melhor para equipes que desejam segurança eficaz sem a fadiga usual de ferramentas.
Inicie um teste gratuito ou solicite uma demonstração para explorar a solução completa.


