O Relatório Internacional de Segurança de IA 2026 é uma das visões gerais mais abrangentes até o momento sobre os riscos representados por sistemas de IA de propósito geral. Ele é compilado por mais de 100 especialistas independentes de mais de 30 países e mostra que, embora os sistemas de IA estejam operando em níveis que pareciam ficção científica há apenas alguns anos, os riscos de uso indevido, mau funcionamento e danos sistemáticos e transfronteiriços são claros.
Ele apresenta um argumento convincente para melhor avaliação, transparência e salvaguardas. Mas uma questão direta permanece pouco explorada: como é a “segurança” quando a IA opera autonomamente contra sistemas reais?
Um resumo dos pontos interessantes do Relatório Internacional de Segurança de IA inclui:
- Pelo menos 700 milhões de pessoas usam sistemas de IA semanalmente, com taxas de adoção mais rápidas do que as do computador pessoal em seus primeiros anos.
- Várias empresas de IA lançaram seus modelos de 2025 com medidas de segurança adicionais depois que os testes de pré-implantação não conseguiram descartar que os sistemas poderiam ajudar não-especialistas a desenvolver armas biológicas. (!!!) (Não está claro se a medida de segurança adicional ainda o impediria completamente)
- Equipes de segurança documentaram ferramentas de IA sendo usadas em ciberataques reais, tanto por atores independentes quanto por grupos patrocinados pelo estado.
O relatório discute longamente as abordagens para gerenciar muitos dos riscos associados à IA – aqui está a nossa perspectiva:
Onde a Aikido concorda com o relatório (e maneiras pelas quais ele poderia ir além)
1. A defesa em camadas é importante
O relatório descreve uma abordagem de defesa em profundidade para a segurança da IA, dividindo-a em três camadas: construir modelos mais seguros durante o treinamento, adicionar controles na implantação e monitorar sistemas depois que eles estão ativos. Concordamos amplamente com a aplicação dessas camadas.
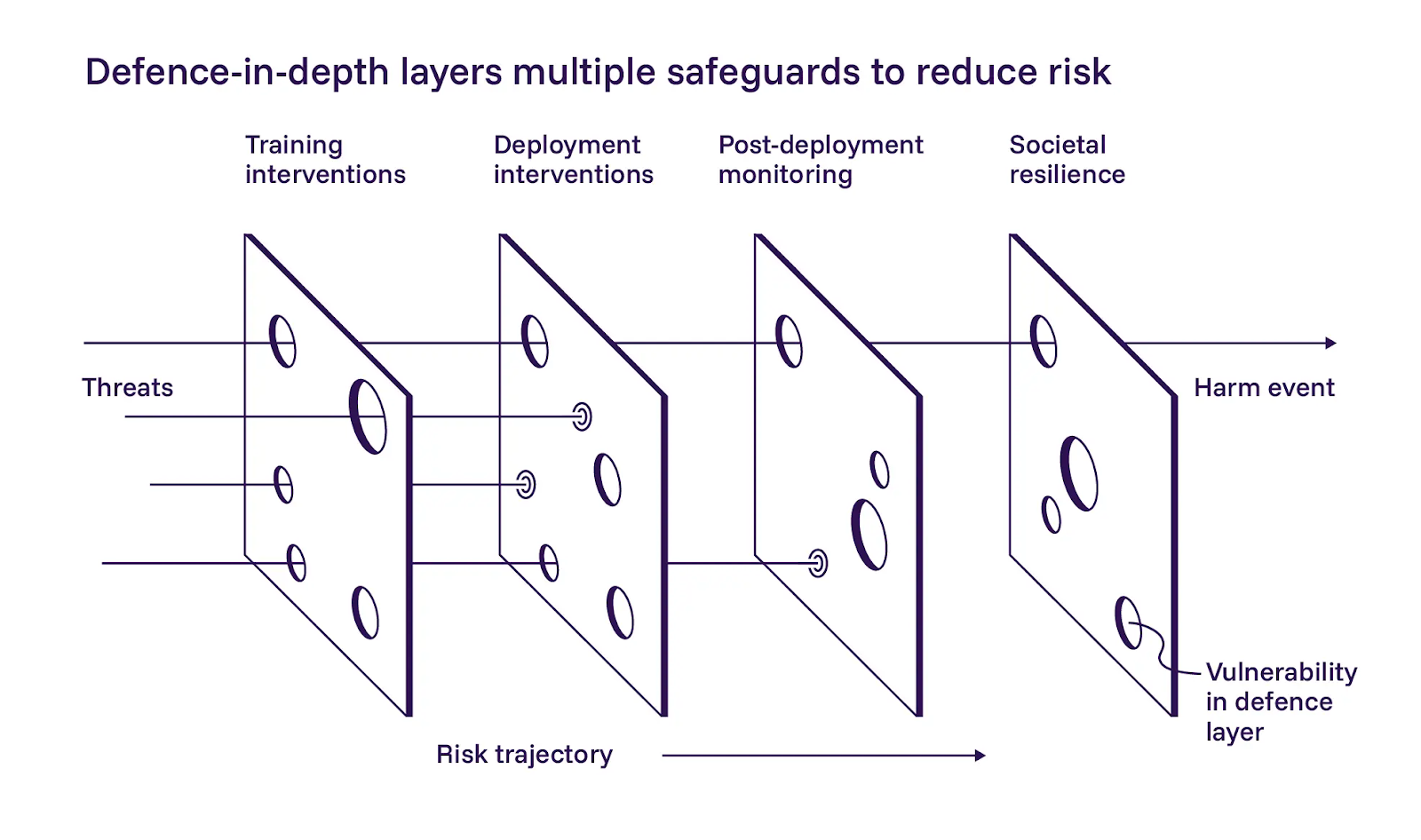
O relatório enfatiza a primeira camada, o desenvolvimento de modelos mais seguros. Eles estão cautelosamente otimistas de que as mitigações baseadas em treinamento podem ajudar, mas também reconhecem que são difíceis de implementar em escala. Embora concordemos que os operadores de IA devem se esforçar ao máximo durante o treinamento, nossa filosofia diverge ligeiramente do relatório neste caso. Não podemos depender de prompts ou instruções para manter sistemas autônomos dentro do escopo. A defesa em camadas só funciona se cada camada puder falhar independentemente.
2. Validação como Requisito de Segurança
O relatório não aprofunda nos detalhes de implementação para a segunda camada, os controles em tempo de implantação, mas acreditamos que é aqui que o progresso mais imediato pode acontecer.
O Relatório Internacional documenta modelos que manipulam suas avaliações de maneiras preocupantes. Alguns encontram atalhos que pontuam bem em testes sem realmente resolver o problema subjacente (reward hacking). Outros intencionalmente têm um desempenho inferior quando detectam que estão sendo avaliados, tentando evitar restrições que pontuações altas poderiam desencadear (sandbagging). Em ambos os casos, os modelos otimizam para algo diferente do objetivo pretendido.
Chegamos à mesma conclusão: uma vez que os sistemas de IA operam autonomamente, não se pode confiar no que eles auto-relatam, em seus níveis de confiança ou em seus rastros de raciocínio. Um agente que valida suas próprias descobertas cria um único ponto de falha disfarçado de redundância. A operação segura exige tratar as descobertas iniciais como hipóteses, reproduzir o comportamento antes de relatar e usar lógica de validação que seja separada da descoberta. Essa validação pode até vir de outro agente de IA.
3. Reduzir o risco antes de permitir que agentes rodem em ambientes de produção
A terceira camada do relatório abrange observabilidade, controles de emergência e monitoramento contínuo depois que os sistemas entram em produção. Isso se alinha com o que vimos em nossas operações.
A operação de caixa preta não é aceitável para sistemas autônomos que interagem com a infraestrutura de produção, então tratamos os mecanismos de parada de emergência como requisitos não negociáveis. Se você não consegue ver o que um agente está fazendo ou pará-lo quando ele sai do controle, você não o está operando com segurança, independentemente de quão bom seja o modelo subjacente.
4. Prompt Injection Requer Restrições Impostas, Não Esperança
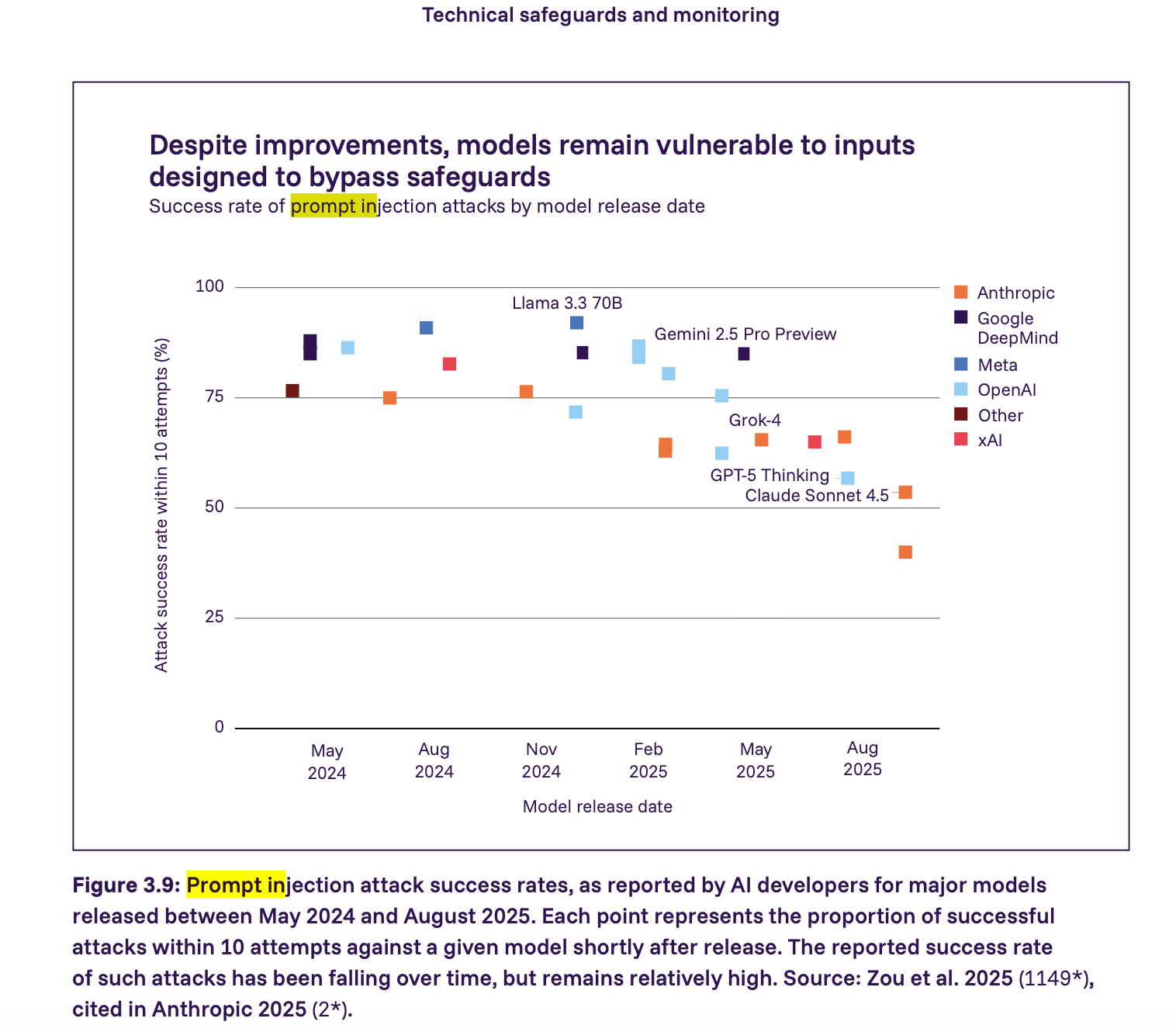
O relatório mostra que os ataques de prompt injection ainda são uma vulnerabilidade séria – muitos grandes modelos em 2025 poderiam ser atacados com sucesso por prompt injection com relativamente poucas tentativas. A taxa de sucesso está caindo, mas permanece relativamente alta. Vamos um passo além do relatório e defendemos que qualquer agente interagindo com conteúdo de aplicação não confiável deve ser considerado vulnerável a prompt injection por padrão. A segurança, neste contexto, provém da imposição de restrições e não da esperança de que os modelos se comportem corretamente.
O Que Acreditamos Que Deve Vir a Seguir
Sistemas, Não Apenas Modelos
O relatório defende fortemente a defesa em profundidade, a transparência e a avaliação. Isso é importante, mas muitos dos problemas mais imediatos ocorrem quando os modelos se conectam a ferramentas, credenciais e ambientes de produção. É por isso que os requisitos em nível de implementação são tão importantes (e necessários). Precisamos traduzir esses princípios em requisitos técnicos concretos que as equipes possam implementar.
Com base na operação de sistemas de pentest de IA em produção, acreditamos que os requisitos mínimos de segurança para sistemas autônomos de IA devem incluir:
- Prevenção de abusos e validação de propriedade
- Controle de escopo imposto no nível da rede
- Isolamento entre raciocínio e execução
- Observabilidade total e controles de emergência
- Residência de dados e garantias de processamento
- Contenção de prompt injection
- Validação e controle de falsos positivos
Descobrimos que estes são os requisitos mínimos aplicáveis para a segurança. Se você omitir qualquer um deles, introduzirá um risco inaceitável no sistema. Detalhes sobre esses requisitos podem ser encontrados em nossa postagem no blog sobre Segurança em Pentest de IA.
Linhas de Base de Segurança como Blocos de Construção de Políticas
O Relatório Internacional de Segurança de IA representa um progresso significativo em direção a uma compreensão compartilhada dos riscos da IA entre governos, pesquisadores e a indústria. O desafio agora é preencher a lacuna entre as descobertas de pesquisa, os frameworks regulatórios e as práticas de implantação no mundo real.
O relatório apresenta alguns cenários de alto risco genuínos e estatísticas preocupantes sobre a rapidez com que as capacidades estão avançando. Dito isso, esta não é uma razão para entrar em pânico ou regulamentar a “IA” como um monólito assustador. O próprio relatório observa que as salvaguardas variam amplamente entre os desenvolvedores e
que mandatos prescritivos podem sufocar a inovação defensiva. Concordamos. A regulamentação deve evitar impor um único caminho de implementação. Em vez disso, as políticas devem definir linhas de base de segurança claras e orientadas a resultados que possam servir como blocos de construção para frameworks mais amplos.
Como parte do movimento para criar frameworks de segurança mais focados em resultados, publicamos nosso documento sobre os Requisitos Mínimos de Segurança para Testes de Segurança Impulsionados por IA. Para equipes que avaliam ferramentas de pentest de IA ou constroem sistemas de segurança autônomos, este guia serve como uma referência neutra em relação a fornecedores. Esperamos que isso ajude as equipes a avaliar ferramentas de pentest de IA, construir sistemas de segurança autônomos mais seguros e contribuir para o estabelecimento de linhas de base claras que funcionem tanto para desenvolvedores quanto para reguladores.


